최신Databricks Certified Data Engineer Associate Exam (Databricks-Certified-Data-Engineer-Associate日本語版) - Databricks-Certified-Data-Engineer-Associate日本語무료샘플문제
문제1
データエンジニアがノートブック上で小規模な概念実証を開発している。ノートブック全体を実行すると、クラスタの使用率が急上昇する。データエンジニアは、開発環境を維持しつつ、リアルタイムの結果を得たいと考えている。
これらの要件を満たすクラスターはどれですか?
データエンジニアがノートブック上で小規模な概念実証を開発している。ノートブック全体を実行すると、クラスタの使用率が急上昇する。データエンジニアは、開発環境を維持しつつ、リアルタイムの結果を得たいと考えている。
これらの要件を満たすクラスターはどれですか?
정답: A
설명: (ExamPassdump 회원만 볼 수 있음)
문제2
データアーキテクトは、以下の形式のテーブルが必要であると判断しました。
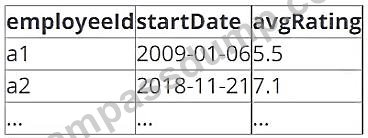
次のコードブロックのうち、既に同じ名前のテーブルが存在するかどうかに関わらず、上記の形式で空のデルタテーブルを作成するためにSQL DDLコマンドを使用するものはどれですか?

データアーキテクトは、以下の形式のテーブルが必要であると判断しました。
次のコードブロックのうち、既に同じ名前のテーブルが存在するかどうかに関わらず、上記の形式で空のデルタテーブルを作成するためにSQL DDLコマンドを使用するものはどれですか?
정답: E
설명: (ExamPassdump 회원만 볼 수 있음)
문제3
データエンジニアがワークスペースUIを使用して、複数のDatabricksジョブとダッシュボードを手動で作成しました。チームは今後、これらのリソースを宣言型自動化バンドル(旧Databricksアセットバンドル)を使用してコードとして管理し、構成をGitリポジトリに保存し、CI/CDを通じて変更をデプロイしたいと考えています。
既存のリソースをバンドルプロジェクトに変換するには、どの方法が有効ですか?
データエンジニアがワークスペースUIを使用して、複数のDatabricksジョブとダッシュボードを手動で作成しました。チームは今後、これらのリソースを宣言型自動化バンドル(旧Databricksアセットバンドル)を使用してコードとして管理し、構成をGitリポジトリに保存し、CI/CDを通じて変更をデプロイしたいと考えています。
既存のリソースをバンドルプロジェクトに変換するには、どの方法が有効ですか?
정답: C
문제4
データ エンジニアは、テーブルから読み取り、データを操作し、新しいテーブルにストリーミング書き込みを実行するように構造化ストリーミング ジョブを構成しました。
データ エンジニアが使用するコード ブロックは次のとおりです。

データ エンジニアが、クエリで利用可能なすべてのデータを必要な数のバッチで処理することだけを望む場合、データ エンジニアは空白を埋めるために次のどのコード行を使用する必要がありますか。
データ エンジニアは、テーブルから読み取り、データを操作し、新しいテーブルにストリーミング書き込みを実行するように構造化ストリーミング ジョブを構成しました。
データ エンジニアが使用するコード ブロックは次のとおりです。
データ エンジニアが、クエリで利用可能なすべてのデータを必要な数のバッチで処理することだけを望む場合、データ エンジニアは空白を埋めるために次のどのコード行を使用する必要がありますか。
정답: B
설명: (ExamPassdump 회원만 볼 수 있음)
문제5
データ エンジニアは、Python 変数 day_of_week が 1 で、Python 変数 review_period が True の場合にのみ、Python プログラムの最後のブロックを実行したいと考えています。
データ エンジニアは、この条件付きで実行されるコード ブロックを開始するために、次のどの制御フロー ステートメントを使用する必要がありますか?
データ エンジニアは、Python 変数 day_of_week が 1 で、Python 変数 review_period が True の場合にのみ、Python プログラムの最後のブロックを実行したいと考えています。
データ エンジニアは、この条件付きで実行されるコード ブロックを開始するために、次のどの制御フロー ステートメントを使用する必要がありますか?
정답: D
설명: (ExamPassdump 회원만 볼 수 있음)
문제6
エンジニアリングマネージャーは、Databricks SQLクエリを使用して、最近のプロジェクトのパフォーマンスを監視したいと考えています。プロジェクトのリリース後1週間は、クエリ結果を1分ごとに更新したいと考えています。しかし、クエリに使用されるコンピューティングリソースが稼働し続け、プロジェクトリリース後1週間を過ぎても組織に多大なコストがかかることを懸念しています。
プロジェクトのリリース後 1 週間を過ぎてもクエリによって組織にコストが発生しないようにするために、エンジニアリング チームが使用できるアプローチは次のどれですか。
エンジニアリングマネージャーは、Databricks SQLクエリを使用して、最近のプロジェクトのパフォーマンスを監視したいと考えています。プロジェクトのリリース後1週間は、クエリ結果を1分ごとに更新したいと考えています。しかし、クエリに使用されるコンピューティングリソースが稼働し続け、プロジェクトリリース後1週間を過ぎても組織に多大なコストがかかることを懸念しています。
プロジェクトのリリース後 1 週間を過ぎてもクエリによって組織にコストが発生しないようにするために、エンジニアリング チームが使用できるアプローチは次のどれですか。
정답: B
설명: (ExamPassdump 회원만 볼 수 있음)
문제7
データ エンジニアは、データ パイプラインの一部として Delta テーブルを使用する必要がありますが、適切な権限があるかどうかがわかりません。
データ エンジニアがテーブルに対する権限を確認できるのは次のどの場所ですか。
データ エンジニアは、データ パイプラインの一部として Delta テーブルを使用する必要がありますが、適切な権限があるかどうかがわかりません。
データ エンジニアがテーブルに対する権限を確認できるのは次のどの場所ですか。
정답: B
설명: (ExamPassdump 회원만 볼 수 있음)
문제8
データエンジニアとデータアナリストがデータパイプラインを共同で開発しています。データエンジニアはPythonを使用してパイプラインのraw、bronze、silverレイヤーを担当し、データアナリストはSQLを使用してパイプラインのgoldレイヤーを担当しています。パイプラインのrawソースはストリーミング入力です。彼らは現在、パイプラインをDelta Live Tablesを使用するように移行したいと考えています。
Delta Live Tablesへの移行時に、パイプラインにどのような変更が必要になりますか?
データエンジニアとデータアナリストがデータパイプラインを共同で開発しています。データエンジニアはPythonを使用してパイプラインのraw、bronze、silverレイヤーを担当し、データアナリストはSQLを使用してパイプラインのgoldレイヤーを担当しています。パイプラインのrawソースはストリーミング入力です。彼らは現在、パイプラインをDelta Live Tablesを使用するように移行したいと考えています。
Delta Live Tablesへの移行時に、パイプラインにどのような変更が必要になりますか?
정답: B
설명: (ExamPassdump 회원만 볼 수 있음)
문제9
データ エンジニアが単一ノード クラスターを使用するシナリオを説明しているのは次のどれですか。
データ エンジニアが単一ノード クラスターを使用するシナリオを説明しているのは次のどれですか。
정답: B
설명: (ExamPassdump 회원만 볼 수 있음)
문제10
次のコマンドのうち、member_id 列の null 値の数を返すものはどれですか。
次のコマンドのうち、member_id 列の null 値の数を返すものはどれですか。
정답: D
설명: (ExamPassdump 회원만 볼 수 있음)
문제11
データエンジニアリングチームは、以下の機能を備えたSaaSアプリケーションからDatabricksデータインテリジェンスプラットフォームに顧客トランザクションを段階的に取り込む必要があります。
更新や削除を含む変更データの取得機能が組み込まれています。
自動的なスキーマ進化
再試行機能と最小限のメンテナンスを備えたサーバーレス実行
OAuthサポートと基本的な監視
どのソリューションがすべての要件を満たしていますか?
データエンジニアリングチームは、以下の機能を備えたSaaSアプリケーションからDatabricksデータインテリジェンスプラットフォームに顧客トランザクションを段階的に取り込む必要があります。
更新や削除を含む変更データの取得機能が組み込まれています。
自動的なスキーマ進化
再試行機能と最小限のメンテナンスを備えたサーバーレス実行
OAuthサポートと基本的な監視
どのソリューションがすべての要件を満たしていますか?
정답: A
설명: (ExamPassdump 회원만 볼 수 있음)